TclHttpd Web Server
This chapter will be part of the 3rd edition of Practical Programming in Tcl and Tk by Brent Welch. Progress on the book proceeds at a glacial pace, so this chapter is being made available to help users of TclHttpd. The original work is in Frame, and this HTML file is automatically generated with minimal effort. Please don't complain about formatting, (get the PDF format instead) but please do provide feedback about content. Direct your email to welch@scriptics.com and put the word "book" or "tclhttpd" into the subject.
This chapter describes TclHttpd, a web server built entirely in Tcl. The web server can be used as a stand-alone server or it can be embedded into applications to web-enable them. TclHttpd provides a Tcl+HTML template facility that is useful for maintaining site-wide look and feel, and an application-direct URL that invokes a Tcl procedure in an application.
T clHttpd started out as about 175 lines of Tcl that could serve up HTML pages and images. The Tcl socket and I/O commands make this easy. Of course, there are lots of features in web servers like Apache or Netscape that were not present in the first prototype. Steve Uhler took my prototype, refined the HTTP handling, and aimed to keep the basic server under 250 lines. I went the other direction, setting up a modular architecture, adding in features found in other web servers, and adding some interesting ways to connect TclHttpd to Tcl applications.
Today TclHttpd is used both as a general-purpose Web server, and as a framework for building server applications. It implements www.scriptics.com, including the Tcl Resource Center and Scriptics' electronic commerce facilities. It is also built into several commercial applications such as license servers and mail spam filters. Instructions for setting up the TclHttpd on your platform are given towards the end of the chapter, on page See The TclHttpd Distribution . It works on Unix, Windows, and Macintosh. You can have the server up and running quickly.
The bulk of this chapter describes the various ways you can extend the server and integrate it into your application. TclHttpd is interesting because, as a Tcl script, it is easy to add to your application. Suddenly your application has an interface that is accessible to Web browsers in your company's intranet or the global Internet. The Web server provides several ways you can connect it to your application:
- Static pages. As a "normal" web server, you can serve static documents that describe your application.
- Domain handlers. You can arrange for all URL requests in a section of your web site to be handled by your application. This is a very general interface where you interpret what the URL means and what sort of pages to return to each request. For example, http://www.scriptics.com/resource is implemented this way. The URL past /resource selects an index in a simple database, and the server returns a page describing the pages under that index.
- Application-Direct URLs. This is a domain handler that maps URLs onto Tcl procedures. The form query data that is part of the HTTP GET or POST request is automatically mapped onto the parameters of the application-direct procedure. The procedure simply computes the page as its return value. There is none of the complexity of the CGI interface. For example, in TclHttpd the URLs under /status report various statistics about the web server's operation.
- Document handlers. You can define a Tcl procedure that handles all files of a particular type. For example, the server has a handler for CGI scripts, HTML files, and HTML+Tcl template files.
- HTML+Tcl Templates. These are web pages that mix Tcl and HTML markup. The server replaces the Tcl using the subst command and returns the result. The server can cache the result in a regular HTML file to avoid the overhead of template processing on future requests. Templates are a great way to maintain common look and feel to a family of web pages, as well as to implement more advanced dynamic HTML features like self-checking forms.
TclHttpd Architecture
This section describes the software architecture of TclHttpd. This explains how the server dispatches requests for URLs to different modules and what basic functions are available to help respond to URL requests. You need to understand this as you go to extend the server's functionality or integrate the server into your own application. As we go along, there will be references to Tcl files in the server's implementation. These are all found in the lib directory of the distribution, and you may find it helpful to read the code to learn more about the implementation. [CD-ROM ref] Figure See The dotted box represents one application that embeds TclHttpd. Document templates and Application Direct URLs provide direct connections from an HTTP request to your application. shows the basic components of the server.
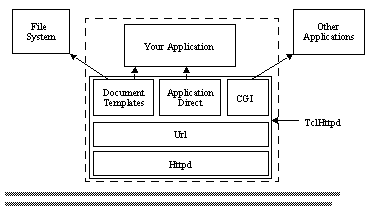
At the core is the Httpd module , which implements the server side of the HTTP protocol. The 'd' in Httpd stands for daemon, which is the name given to system servers on UNIX . This module manages network requests, dispatches them to the Url module, and provides routines used to return the results to requests.
The Url module divides the web site into domains , which are subtrees of the URL hierarchy provided by the server. The idea is that different domains may have completely different implementations. For example, the Document domain ( doc.tcl ) maps its URLs into files and directories on your hard disk, while the Application-Direct domain ( direct.tcl ) maps URLs into Tcl procedure calls within your application. The CGI domain (cgi.tcl) maps URLs onto other programs that compute web pages.
A Simple URL Domain
You can implement new kinds of domains that provide your own interpretation of a URL. This is the most flexible interface available to extend the web server. You provide a callback that is invoked to handle every request in a domain, or subtree, of the URL hierarchy. The callback interprets the URL, computes the page content, and returns the data using routines from the Httpd module.
Example See A simple URL domain. defines a simple domain that always returns the same page to every request. This example shows the basic structure of a domain handler and introduces some useful support procedures. The domain is registered with the Url_PrefixInstall command. The arguments to Url_PrefixInstall are the URL prefix and a callback that is called to handle all URLs that match that prefix. In the example, all URLs that start with /simple are dispatched to the SimpleDomain procedure.
A simple URL domain.

Url_PrefixInstall /simple [list SimpleDomain /simple]
proc SimpleDomain {prefix sock suffix} {
set html "<title>A simple page</title>\n"
append html "<h1>$prefix$suffix</h1>\n"
append html "<h1>Date and Time</h1>\n"
append html [clock format [clock seconds]]
if {[info exist data(query)]} {
append html "<h1>Query Data</h1>\n"
foreach {name value} [Url_DecodeQuery $data(query)] {
}
The SimpleDomain handler illustrates several properties of domain handlers. The sock and suffix arguments to SimpleDomain are appended by Url_Dispatch when it invokes the domain handler. The suffix parameter is the part of the URL after the prefix. The prefix is passed in as part of the callback definition so the domain handler can recreate the complete URL. For example, if the server receives a request for the url /simple/page , then the prefix is /simple , the suffix is /request .
Connection State and Query Data
The sock parameter is a handle on the socket connection to the remote client. This variable is also used to name a state variable that the Httpd module maintains about the connection. The name of the state array is Httpd$sock , and SimpleDomain uses upvar to get a more convenient name for this array (i.e., data ):
}
Returning Results
Finally, once the page has been computed, the Httpd_ReturnData procedure is used to return the page to the client. This takes care of the HTTP protocol as well as returning the data. There are two related procedures, Httpd_ReturnFile and Httpd_Redirect . The first returns the contents of a file as the result of the transaction. It is called like this:
Httpd_ReturnFile $sock mimetype filename
The Httpd_Redirect procedure generates a 302 return code that causes the remote client to fetch a different URL. This is a very useful trick employed in complex page flows. It is invoked like this:
Application Direct URLs
The Application Direct domain implementation provides the simplest way to extend the web server. It hides the details associated with query data, decoding URL paths, and returning results. All you do is define Tcl procedures that corresond to URLs. Their arguments are automatically matched up to the query data. The Tcl procedures compute a string that is the result data, which is usually HTML. That's all there is to it.
The Direct_Url procedure defines a URL prefix and a corresponding Tcl command prefix. Any URL that begins with the URL prefix will be handled by a corresponding Tcl procedure that starts with the Tcl command prefix. This is shown in Example See Application Direct URLs :
Application Direct URLs
return "<html><head><title>Demo page</title></head>\n\
<a href=/demo/time>What time is it?</a>\n\
Data: <input type=text name=data>\n\
<input type=submit name=echo value='Echo Data'>\n\
proc Demo/time {{format "%H:%M:%S"}} {
return [clock format [clock seconds] -format $format]
# Compute a page that echos the query data
set html "<head><title>Echo</title></head>\n"
}
Example See Application Direct URLs defines /demo as an Application Direct URL domain that is implemented by procedures that begin with Demo . There are just three URLs defined:
/demo/echo
The /demo page displays a hypertext link to the /demo/time page, and a simple form that will be handled by the /demo/echo page. This page is static, and so there is just one return command in the procedure body. Each line of the string ends with:
\n\
This is just a formatting trick to let me indent each line in the procedure, but not have the line indented in the resulting string. Actually, the \-newline will be replaced by one space, so each line will be indented one space. You can leave those off and the page will display the same in the browser, but when you view the page source you'll see the indenting. Or, you could not indent the lines in the string, but then your code looks a little funny.
The /demo/time procedure just returns the result of clock format . It doesn't even bother adding <html> , <head> , or <body> tags, which you can get away with in today's browsers. A simple result like this is also useful if you are using programs to fetch information via HTTP requests.
Using Query Data
The /demo/time procedure is defined with an optional format argument. If a format value is present in the query data then it overrides the default value given in the procedure definition.
The /demo/echo procedure creates a table that shows its query data. Its args parameter gets filled in with a name-value list of all query data. You can have named parameters, named parameters with default values, and the args parameter in your application-direct URL procedures. The server automatically matches up incoming form values with the procedure declaration. For example, suppose you have an application direct procedure declared like this:
proc Demo/param { a b {c cdef} args} { body }
You could create an HTML form that had elements named a , b , and c , and specified /demo/param for the ACTION parameter of the FORM tag. Or, you could type the following into your browser to embed the query data right into the URL:
/demo/param?a=5&b=7&c=red&d=%7ewelch&e=two+words
In this case, when your procedure is called, a is 5 , b is 7 , c is red , and the args parameter becomes a list of:
d ~welch e {two words}
The %7e and the + are special codes for non-alphanumeric characters in the query data. Normally this encoding is taken care of automatically by the Web browser when it gets data from a form and passes it to the Web server. However, if you type query data directly, you need to think about the encoding. The regular expression chapter shows the Url_Decode procedure that decodes these values. This procedure is used by the application direct domain implementation, so your procedure argument values are already decoded.
If parameters are missing from the query data they either get the default values from the procedure definition, or the empty string. Consider this example:
Returning Other Content Types
The default content type for application direct URLs is text/html . You can specify other content types by using a global variable with the same name as your procedure. (Yes, this is a crude way to craft an interface.) Example See Alternate types for Appliction Direct URLs. shows part of the faces.tcl file that implements an interface to a database of picons, or personal icons, that is organized by user and domain names. The idea is that the database contains images corresponding to your email correspondents. The Faces_ByEmail procedure, which is not shown, looks up an appropriate image file. The application direct procedure is Faces/byemail , and it sets the global variable Faces/byemail to the correct value based on the filename extension. This value is used for the Content-Type header in the result part of the HTTP protocol.
Document Types
The Document domain maps URLs onto files and directories. It provides more ways to extend the server by registering different document type handlers. This occurs in a two step process. First the type of a file is determined by its suffix. The mime.types file contains a map from suffixes to MIME types such as text/html or image/gif . This map is controlled by the Mtype module in mtype.tcl . Second, the server checks for a Tcl procedure with the appropriate name:
Doc_mimetype
The matching prcedure, if any, is called to handle the URL request. The procedure should use routines in the Httpd module to return data for the request. If there is no matching Doc_mimetype procedure, then the default document handler uses Httpd_ReturnFile and specifies the Content Type based on the file extension.
You can make up new types to support your application. For example, the HTML+Tcl templates use the " .tml " suffix that is mapped to the application/x-tcl-template type. The TclHttpd distribution also includes support for files with a .snmp extension that implement a template-based web interface to the Scotty SNMP Tcl extension.
HTML + Tcl Templates
The template system uses HTML pages that embed Tcl commands and Tcl variable references. The server replaces these using the subst command and returns the results. The server comes with a general template system, but using subst is so easy you can create your own template system. The general template framework has these components:
- Each .html file has a corresponding .tml template file. This feature is enabled with the Doc_CheckTemplates command in the server's configuration file. Normally, the server returns the .html file unless the corresponding .tml file has been modified more recently. In this case the server processes the template, caches the result in the .html file, and returns the result.
- A dynamic template (e.g., a form handler) must be processed each time it is requested. If you put the Doc_Dynamic command into your page it turns off the caching of the result in the .html page. The server responds to a request for a .html page by processing the .tml page.
- The server creates a page global Tcl variable that has context about the page being processed. Table X lists the elements of the page array.
- The server initializes the env global Tcl variable with similar information, but in the standard way for CGI scripts. Table Y lists the elements of the env array that are set by Cgi_SetEnv in cgi.tcl .
- The server supports per-directory " .tml " files that contain Tcl source code. These files are sourced by the server from the URL document root down to the directory containing a template file. These files are designed to contain procedure definitions and variable settings that are shared among pages. The server compares the modify time of these files against the template file and will process the template if these .tml files are newer than the cached .html file. So, by modifying the " .tml " file in the root of your URL hierarchy you invalidate all the cached .html files.
- The server supports a script library for the procedures called from templates. The Doc_TemplateLibrary procedure registers this directory. The server adds the directory to its auto_path , which assumes you have a tclIndex or pkgIndex.tcl file in the directory so the procedures are loaded when needed.
The advantage of putting procedure definitions in the library is that they are defined one time but executed many times. This works well with the Tcl byte-code compiler. The disadvantage is that if you modify procedures in these files you have to explicitly source them into the server for these changes to take effect.
The advantage of putting code into .tml files is that changes are picked up immediately with no effort on your part. However, that code is only run one time, so the byte-code compiler just adds overhead.
Templates for Site Structure
The next few examples show a simple template system used to maintain a common look at feel across the pages of a site. Example See A one-level site structure. shows a simple one-level site definition that is kept in the root .tml file. This structure lists the title and URL of each page in the site:
}
Each page includes two commands, SitePage and SiteFooter that generate HTML for the navigational part of the page. Between these commands is regular HTML for the page content. Example See A HTML + Tcl template file. shows a sample template file:
A HTML + Tcl template file.
[SitePage "New Machine Setup"]
This page describes the steps to take when setting up a new
computer in our environment. See
<a href=/ordering.html>Ordering Computers</a>
for instructions on ordering machines.
<li>Unpack and setup the machine.
<li>Use the Network control panel to set the IP address
[SiteFooter]
The SitePage procedure takes the page title as an argument. It generates HTML to implement a standard navigational structure. Example See SitePage template procedure. has a simple implementation of SitePage :
}
The foreach loop that computes the simple menu of links turns out to be useful in many places. Example See SiteMenu and SiteFooter template procedures. splits out the loop and uses it in the SitePage and SiteFooter procedures. This version of the templates creates a left column for the navigation and a right column for the page content:
SiteMenu and SiteFooter template procedures.
set html "<html><head><title>$title</title></head>\n\
<body bgcolor=$site(bg) text=$site(fg)>\n\
<img src='$site(mainlogo)'>\n\
[SiteMenu <br> $site(pages)]\n\
<font size=-1>[SiteMenu | $site(pages)]</font>\n\
if {[string compare $page(url) $url] == 0} {
}
Of course, a real site will have more elaborate graphics and probably a two-level, three-level, or more complex tree structure that describes its structure.You can also define a family of templates so that each page doesn't have to fit the same mold. Once you start using templates, it is fairly easy to both change the template implementation and to move pages around among different sections of your web site.
There are many other applications for "macros" that make repetitive HTML coding chores easy. Take, for example, the link to /ordering.html in Example See A HTML + Tcl template file. . The proper label for this is already defined in $site(pages) , so we could introduce a SiteLink procedure that uses this:
Form Handlers
Forms and form handling programs go together. The form is presented to the user on the client machine. The form handler runs on the server after the user fills out the form and hits the submit button. The form presents input widgets like radiobuttons, checkbuttons, selection lists, and text entry fields. Each of these widgets is assigned a name, and each widget gets a value based on the users input. The form handler is a program that looks at the names and values from the form and computes the next page for the user to read.
CGI is a standard way to hook external programs to web servers for the purpose of processing form data. CGI has a special encoding for values so they can be transported safely. The encoded data is either read from standard input or taken from the command line. The CGI program decodes the data, processes it, and writes a new HTML page on its standard output. The Guestbook chapter describes writing CGI scripts in Tcl.
TclHttpd provides alternatives to CGI that are more efficient because they are built right into the server. This eliminates the overhead that comes from running an external program to compute the page. Another advantage is that the Web server can maintain state between client requests simply in Tcl variables. If you use CGI, you must use some sort of database or file storage to maintain information between requests.
Application Direct Handlers
The server comes with several built-in forms handlers that you can use with little effort. The /mail/forminfo URL will package up the query data and mail it to you. You use form fields to set various mail headers, and the rest of the data is packaged up into a Tcl-readable mail message. Example See Mail form results with /mail/forminfo. shows a form that uses this handler. Other built in handlers are described starting at page See Debugging
Mail form results with /mail/forminfo.
<form action=/mail/forminfo method=post>
<input type=hidden name=sendto value=mailreader@my.com>
<input type=hidden name=subject value="Name and Address">
<tr><td>Name</td><td><input name=name></td></tr>
<tr><td>Address</td><td><input name=addr1></td></tr>
<tr><td> </td><td><input name=addr2></td></tr>
<tr><td>City</td><td><input name=city></td></tr>
<tr><td>State</td><td><input name=state></td></tr>
<tr><td>Zip/Postal</td><td><input name=zip></td></tr>
</form>
The mail message sent by /mail/forminfo is shown in Example See Mail message sent by /mail/forminfo . It is easy to write a script that strips the headers, defines a data procedure, and uses eval to process the message body. Whenever you send data via email, if you format it with Tcl list structure you can process it quite easily.
}
Template Form Handlers
The drawback of using the built-in form handlers is that you have to modify their Tcl implementation to change the resulting page. Another approach is to use templates for the result page that embed a command that handles the form data. The Mail_FormInfo procedure, for example, mails form data. It takes no arguments. Instead, it looks in the query data for sendto and subject values, and if they are present it sends the rest of the data in an email. It returns an HTML comment that flags that mail was sent.
When you use templates to process form data you need to turn off result caching because the server must process the template each time the form is submitted. To turn off caching, embed the Doc_Dynamic command in your form handler pages, or set the page(dynamic) variable to 1.
Example See A self-checking form. shows a name and address form. This form is on a page that posts the form data to itself. Once all the data has been filled in correctly, the Form_Check procedure in Example See The Form_Check form handler. redirects to the next page in the flow.
A self-checking form.
<form action=$page(url) method=post>
<input type=hidden name=form value=NameAddr>
[Form_Check nextpage.html mark {email first last addr1 city zip}]
if {[info exist mark($name)]} {
append _ "<tr><td>$mark($name) $label</td>\n"
append _ "<tr><td>$label</td>\n"
</form>
This page embeds a foreach loop to make generation of the HTML table for the form easier. The loop appends to the _ variable, which is used by convention for this purpose in web pages. The form::value procedure, which comes with TclHttpd, is designed for self-posting forms. It returns:
name="name" value="value"
The value is the value of the form element based on incoming query data, or just the empty string if the query value for name is undefined. This way the form can post to itself and retain values from the previous version of the page.
The Form_Check form handler.
proc Form_Check {nextpage markVar required} {
if {[info exist page(query)]} {
if {![info exist query($field)] ||
[string length $query($field)] == 0} {
# No missing fields, so advance to the next page.
# In practice, you must save the existing fields
}
The Doc_Redirect procedure raises a special error that causes TclHttpd to redirect the client browser to a different page. Otherwise, the Form_Check procedure defines an element of the mark array for each missing field. The code in Example See A self-checking form. uses this to flag missing fields. In practice, your form handler should do something with the good data, such as put it into a database.
As a matter of style, there is a bit too much code inside the HTML page in Example See A self-checking form. . You could consider combining the logic that displays the form with the logic that checks for required fields. In this case the HTML page has a single call to your procedure that implements "both sides" of the form: the HTML input form and the Tcl code that validates the field and saves the results.This approach is useful if you re-use the same form on different pages.
The TclHttpd Distribution
Get the TclHttpd distribution from the CD-ROM, or find it on the Internet at:
Quick Start
Unpack the tar file or the zip file and you can run the server from the httpd.tcl script in the bin directory. On UNIX:
tclsh httpd.tcl -port 80
This command will start the web server on the standard port (80). By default it uses port 8015 instead. If you run it with the -help flag it will tell you what command line options are available. If you use wish instead of tclsh then a simple Tk user interface is displayed that shows how many hits the server is getting.
On Windows you can double-click the httpd.tcl script to start the server. It will use wish and display the user interface. Again it will start on port 8015. You will need to create a shortcut that passes the -port argument, or edit the associated configuration file to change this. Configuring the server is described later.
Once you have the server running you can connect to it from your web browser. Use this URL if you are running on the default (non-standard) port:
Inside the Distribution
The TclHttpd distribution is organized into the following directories:
-
bin
This has sample startup scripts and configuration files. The httpd.tcl script runs the server. The tclhttpd.rc file is the standard configuration file. The minihttpd.tcl file is the 250-line version. The torture.tcl file has some scripts that you can use to fetch many URLs at once from a server. -
lib
This has all the Tcl sources. In general, each file provides a package. You will see the package require commands partly in bin/httpd.tcl and partly in bin/tclhttpd.rc . The idea is that the only the core packages are required by httpd.tcl , and different applications can tune what packages are needed by adjusting the contents of tclhttpd.rc . -
htdocs
This is a sample URL tree that demonstrates the features of the web server. There is also some documentation there. One directory to note is htdocs/libtml , which is the standard place to put site-specific Tcl scripts used with the Tcl+HTML template facility. -
src
There are a few C source files for a some optional packages. These have been precompiled for some platforms, and you can find the compiled libraries back under lib/Binaries in platform-specific subdirectories.
Server Configuration
TclHttpd configures itself with three main steps. The first step is to process the command line arguments described in Table See Basic TclHttpd Parameters . The arguments are copied into the Config Tcl array. Anything not specified on the command line gets a default value. The next configuration step is to source the configuration file. The default configuration file is named tclhttpd.rc in the same directory as the startup script (i.e., bin/tclhttpd.rc ). This file can override command line arguments by setting the Config array itself. This file also has application-specific package require commands and other Tcl commands to initialize the application. Most of the Tcl commands used during initialization are described in the rest of this section. The final step is to actually start up the server. This done back in the main httpd.tcl script.
For example, to start the server for the document tree under /usr/local/htdocs and your own email address as webmaster, you can execute this command to start the server:
tclsh httpd.tcl -docRoot /usr/local/htdocs -webmaster welch
Alternatively, you can put these settings into a configuration file, and start the server with that configuration file:
tclsh httpd.tcl -config mytclhttpd.rc
In this case the mytclhttpd.rc file could contain these commands to hard-wire the document root and webmaster email. In this case the command line arguments cannot override these settings:
Command Line Arguments
There are several parameters you may need to set for a standard web server. These are shown below in Table See Basic TclHttpd Parameters . The command line values are mapped into the Config array by the httpd.tcl startup script.
Server Name and Port
The name and port parameters define how your server is known to Web browsers. The URLs that access your server begin with
http:// name : port /
If the port number is 80 you can leave out the port specification. The call that starts the server using these parameters is found in httpd.tcl as:
Httpd_Server $Config(name) $Config(port) $Config(ipaddr)
Specifying the IP address is only necessary if you have several network interfaces (or several IP addresses assigned to one network interface) and want the server to listen to requests on a particular network address. Otherwise, by default server accepts requests from any network interface.
User and Group ID
The user and group ID are used on UNIX systems with the setuid and setgid system calls. This lets you start the server as root, which is necessary to listen on port 80, and then switch to a less privileged user account. If you use Tcl+HTML templates that cache the results in HTML files, then you need to pick an account that can write those files. Otherwise you may want to pick a very unprivileged account.
The setuid Tcl command is implemented by a C extension found under the src directory. If you have not compiled this for your platform, then the attempt to change user ID gracefully fails. See the README file in the src directory for instructions on compiling and installing the extensions found there.
Webmaster Email
The webmaster email address is used for automatic error reporting in the case of server errors. This is defined in the configuration file with the following command:
Document Root
The document root is the directory that contains the static files, templates, cgi scripts, and so on that make up your web site. By default the httpd.tcl script uses the htdocs directory next to the directory containing httpd.tcl. It is worth noting the trick used to locate this directory:
file join [file dirname [info script]] ../htdocs
The info script command returns the full name of the http.tcl script, file dirname computes its directory, and file join finds the adjacent directory. The path ../htdocs works with file join on any platform. The default location of the configuration file is found in a similar way:
file join [file dirname [info script]] tclhttpd.rc
The configuration file initializes the document root with this call:
Other Document Settings
The Doc_IndexFile command sets a pattern used to find the index file in a directory. The command used in the default configuration file is
Doc_IndexFile index.{htm,html,tml,subst}
If you invent other file types with different file suffixes, you can alter this pattern to include them. This pattern will be used by the Tcl glob command.
The Doc_PublicHtml command is used to define "home directories" on your HTML site. If the URL begins with ~username, then the web server will look under the home directory of username for a particular directory. The command in the default configuration file is:
Doc_PublicHtml public_html
For example, if my home directory is /home/welch , then the URL ~welch maps to the directory /home/welch/public_html . If there is no Doc_PublicHtml command, then this mapping does not occur.
You can register two special pages that are used when the server encounters an error it the user specifies an unknown URL. The default configuration file has these commands:
Doc_NotFoundPage notfound.html
These files are treated like templates in that they are passed through subst in order to include the error information or the URL of the missing page. These are pretty crude templates compared to the templates described earlier. You can only count on the Doc and Httpd arrays being defined. Look at the Doc_SubstSystemFile in doc.tcl for the truth about how these files are processed.
Document Templates
The template mechanism has two main configuration options. The first specifies an additional library directory that contains your application-specific scripts. This lets you keep your application-specific files separate from the TclHttpd implementation. The command in the default configuration file specifies the libtml directory of the document tree:
Log Files
The server keeps standard format log files. The Log_SetFile command defines the base name of the log file. The default configuration file uses this command:
Log_SetFile /tmp/log$Config(port)_
By default the server rotates the log file each night at midnight. Each day's log file is suffixed with the current date (e.g., /tmp/logport_990218 .) The error log, however, is not rotated, and all errors are accumulated in /tmp/logport_error.
The log records are normally flushed every few minutes to eliminate an extra I/O operation on each HTTP transaction. You can set this period with Log_FlushMinutes . If minutes is 0, the log is flushed on every HTTP transaction. The default configuration file contains:
CGI Directories
You can register a directory that contains CGI programs with the Cgi_Directory command. This command has the intersting effect of forcing all files in the directory to be executed as CGI scripts, so you cannot put normal HTML files there. The default configuration file contains:
Cgi_Directory /cgi-bin
This means the cgi-bin directory under the document root is a CGI directory. If you supply another argument to Cgi_Directory , then this is a file system directory that gets mapped into the URL defined by the first argument.
You can also put CGI scripts into other directories and use the .cgi suffix to indicate they should be executed as CGI scripts. The various file types supported by the server are described later.
The cgi.tcl file has some additional parameters that you can only tune by setting some elements of the Cgi Tcl array. See the comments in the beginning of that file for details.
Standard Application-Direct URLs
The server has several modules that provide application-direct URLs. These application-direct URL lets you control the server or examine its state from any Web browser. You can look at the implementation of these modules as examples for your own application.
Status
The /status URL is implemented in the status.tcl file. The status module implements the display of hit counts, document hits, and document misses (i.e., documents not found). The Status_Url command enables the application-direct URLs and assigns the top-level URL for the status module. The default configuration file contains this command:
Status_Url /status
Assuming this configuration, the following URLs are implemented:
Debugging
The /debug URL is implemented in the debug.tcl file. The debug module has several useful URLs that let you examine variable values and other internal state. It is turned on with this command in the default configuration file:
Debug_Url /debug
Table See Debug application-direct URLs. lists the /debug URLs. These URLs often require parameters that you can specify directly in the URL. For example, the /debug/echo URL echoes its query parameters:
http://yourserver:port/debug/echo?name=value&name2=val2
The sample URL tree that is included in the distribution includes the file htdocs/hacks.html . This file has several small forms that use the /debug URLS to examine variables and source files. Example See The /debug/source application-direct URL implementation. shows the implementation of /debug/source . You can see that it limits the files to the main script library and to the script library associated with document templates. It may seem dangerous to have these facilities, but I reason that because my source directories are under my control it cannot hurt to reload any source files. In general the library scripts just contain procedure definitions and no global code that might reset state inappropriately. In practice, the ability to tune (i.e., fix bugs) in the running server has proven useful to me on many occassions. It lets you evolve your application without restarting it!
The /debug/source application-direct URL implementation.
set source [file tail $source]
if {[info exists Doc(templateLibrary)]} {
lappend dirlist $Doc(templateLibrary)
set file [file join $dir $source]
set error [catch {uplevel #0 [list source $file]} result]
set html "<title>Source $source</title>\n"
append html "<H1>Error in $source</H1>\n"
append html "<pre>$result<p>$errorInfo</pre>"
append html "<H1>Reloaded $source</H1>\n"
}
Administration
The /admin URL is implemented in the admin.tcl file. The admin module lets you load URL redirect tables, and it provides URLs that reset some of the counters maintained by the server. It is turned on with this command in the default configuration file:
Admin_Url /admin
Currently there is only one useful admin URL. The /admin/redirect/reload URL sources the file named redirect in the document root. This file is expected to contain a number of Url_Redirect commands that establish URL redirects. These are useful if you change the names of pages and want the old names to still work.
The administration module has a limited set of application-direct URLs because the simple application-direct mechanism doesn't provide the right hooks to check authentication credentials. The HTML+Tcl templates work better with the authentication schemes.
Sending Email
The /mail URL is implemented in the mail.tcl file. The mail module implements various form handlers that email form data. Currently it is UNIX only as it uses /usr/lib/sendmail to send the mail. It is turned on with this command in the default configuration file:
Mail_Url /mail
The following application-direct URLs are useful form handlers. You can specify them as the ACTION parameter in your <FORM> tags.
The mail module provides two Tcl procedures that are generally useful. The MailInner procedure is the one that sends mail. It is called like this:
MailInner sendto subject from type body
The sendto and from arguments are email addresses. The type is the Mime type (e.g., text/plain or text/html ) and appears in a Content-Type header. The body contains the mail message without any headers.
The Mail_FormInfo procedure is designed for use in HTML+Tcl template files. It takes no arguments, but insteads looks in current query data for its parameters. It expects to find the same arguments as the /mail/forminfo direct URL. Using a template with Mail_FormInfo gives you more control over the result page than posting directly to /mail/forminfo , and is illustrated in See Mail form results with /mail/forminfo. .